契丹神童
04月10日
通过 OCRmyPDF 实现在扫描版 PDF 中检索文字
| 本文为付费栏目文章,您已订阅,可阅读全文 |
随着手机端扫描软件的普及,很多人越来越多地把纸质文件扫描成电子版,便于日后的查看和调用。我就习惯把收到的重要纸质账单、合同等文件扫描后保存在电脑上。但这上面的文字都是以图片的形式存在 PDF 文件中的,所以往往会遇到这样的问题:
- 无法通过文字搜索快速定位到关键字;
- 无法直接选择文档中的文字进行复制。
这时我们需要一个 OCR 工具来帮你完成这个需求。OCR,全称 Optical Character Recognition,即光学字符识别,是指对图像中的内容进行分析识别处理,以获取其中的文字信息的过程。
例如在使用文档生产力工具大厂 Readdle 出品的 Scanner Pro 扫描文件时,可以通过界面右上角的「•••」选择开启「识别文本(OCR)」选项,来对刚扫描得到的文档进行 OCR 处理,如下方左图所示。这样就可以在另外的 PDF 阅读器(如 PDF Expert)中搜索关键字,以及选择其中的文字以进行复制、查词等进一步操作,如下方右图所示。
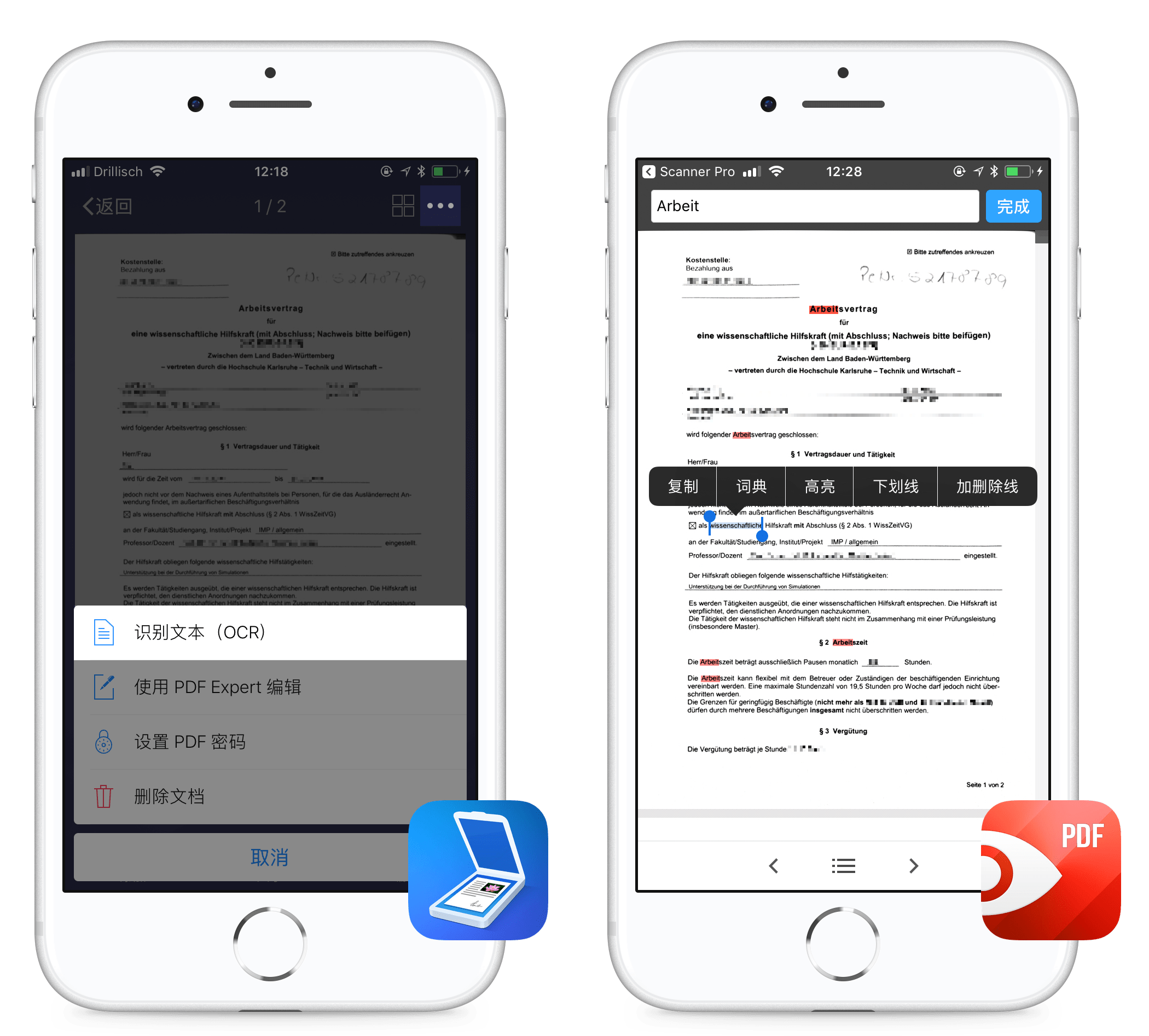
scanner_pro
也有一些其它的 PDF 文档阅读工具如 Adobe Acrobat 提供 OCR 功能支持,但这些工具有两个毛病:
其一、往往都是收费软件;
其二、这些工具多是独立软件,不能作为某个工作流的一环被使用,因此无法完成像是「一次性对多个文件进行批量处理」这样的操作。
安装 OCRmyPDF
OCRmyPDF 的安装方法非常简单,通过 Homebrew 即可安装,在终端中运行如下命令:
brew install ocrmypdf
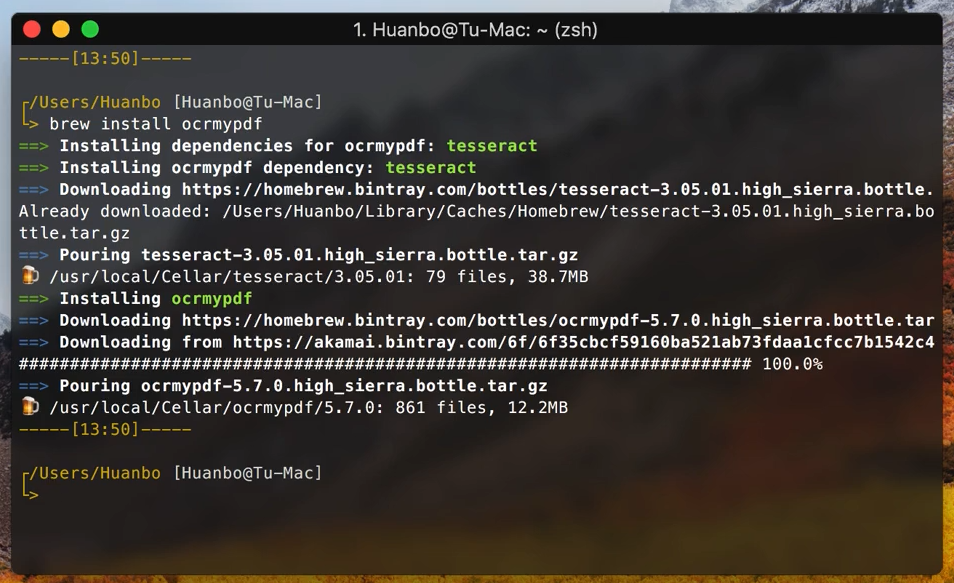
安装 OCRmyPDF
安装过程中会同时安装它所依赖的 Tesseract。安装 Tesseract 时会在以下路径下默认下载好用于识别英文的语言包:
需注意其中 3.05.01 为当前 Tesseract 的版本。
- 简体中文:chi_sim.traineddata
- 繁体中文:chi_tra.traineddata
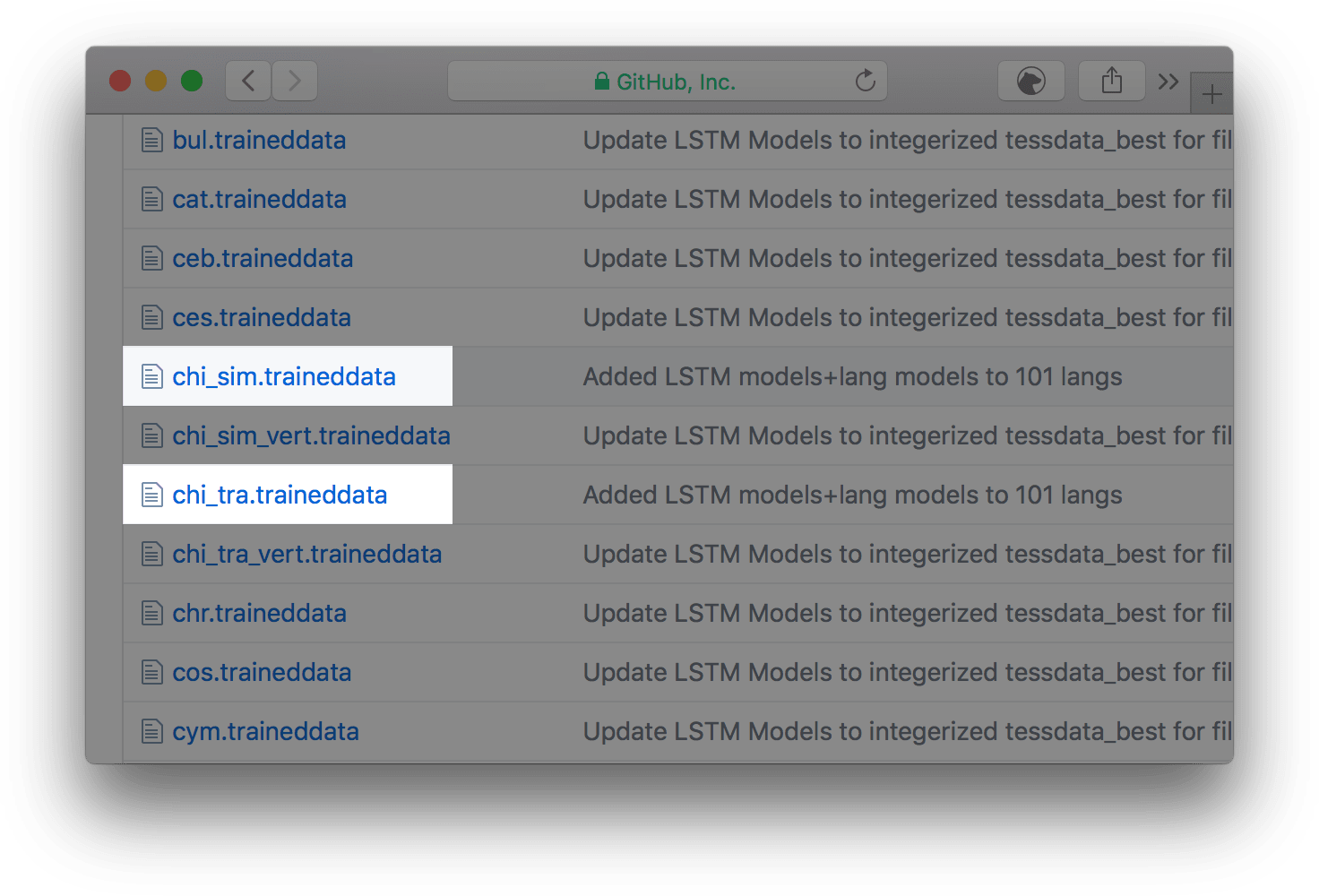
两个中文语言包
点开语言包对应的链接后点击页面中的「Download」。
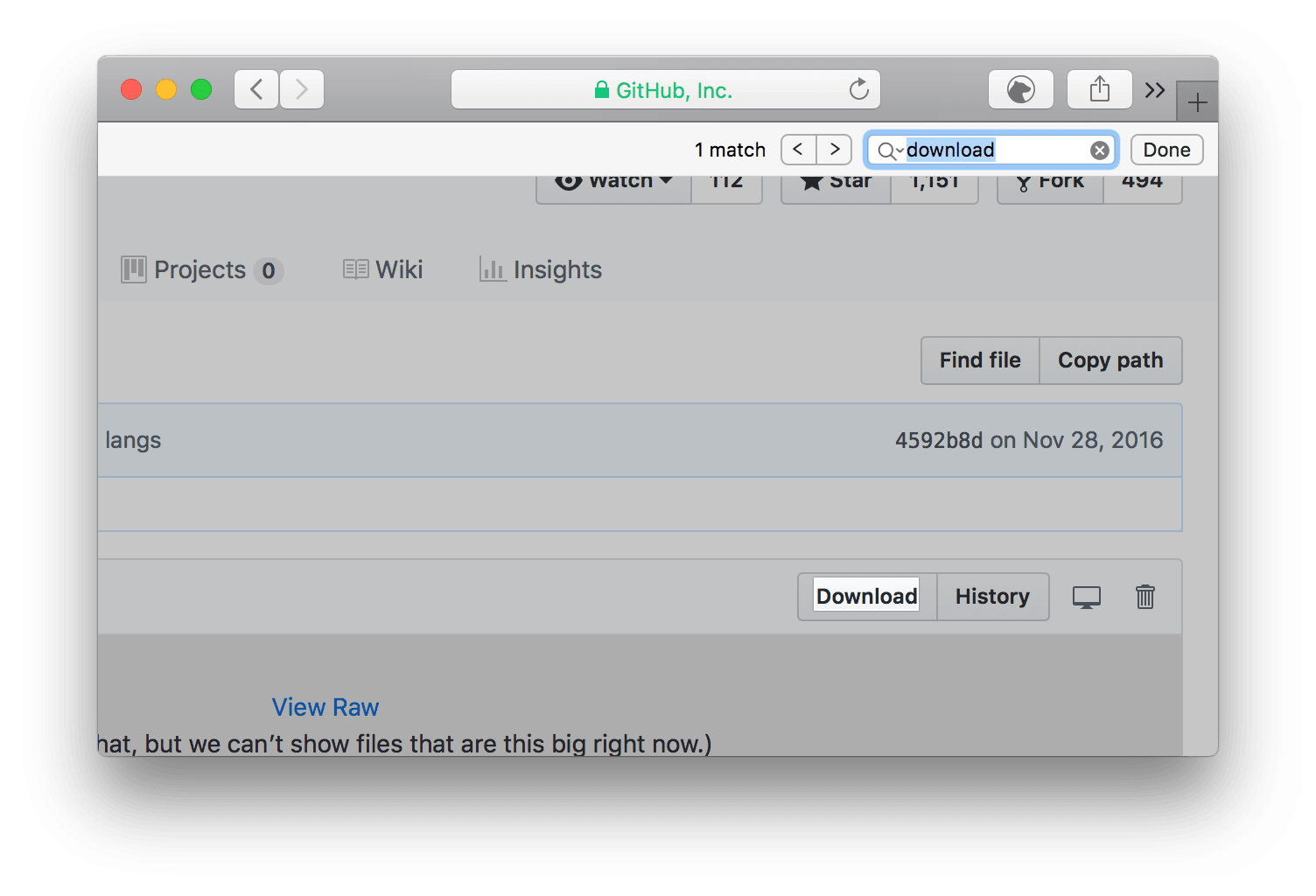
下载语言包
下载之后将文件复制进上面的路径中即可。
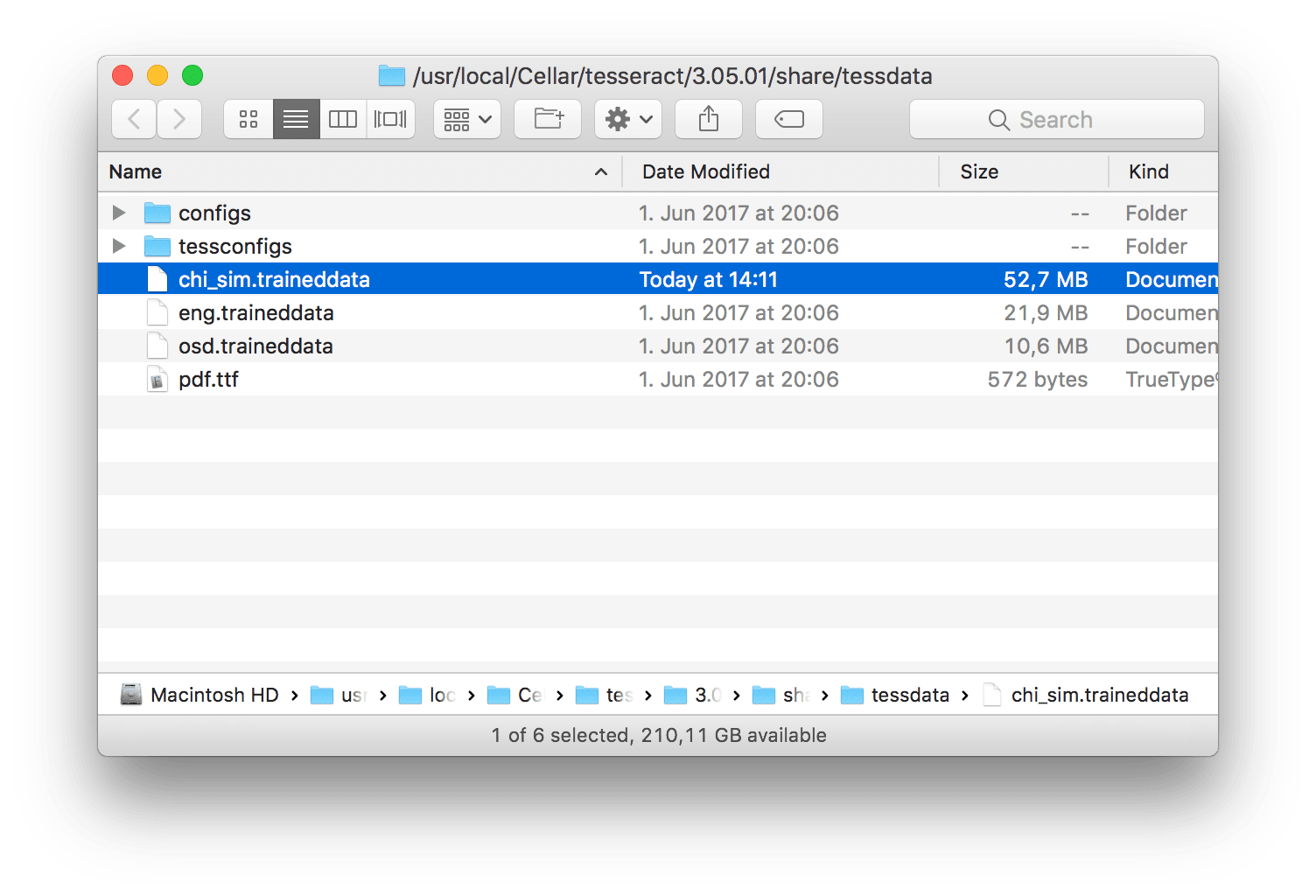
将中文语言包复制进指定路径
当然,也可以选择通过终端下载:
# -o 后面是下载文件的存储路径以及文件名
wget -o /usr/local/Cellar/tesseract/3.05.01/share/tessdata/chi_sim.traineddata https://github.com/tesseract-ocr/tessdata/raw/master/chi_sim.traineddata
或
# -d 后面是下载文件的存储路径
aria2c -d /usr/local/Cellar/tesseract/3.05.01/share/tessdata/ https://github.com/tesseract-ocr/tessdata/raw/master/chi_sim.traineddata
(以上两个下载工具 wget 及 aria2 也需要通过 Homebrew 安装。)
OCRmyPDF 的基本使用
安装完成后,就可以开始处理 PDF 文档了。
OCRmyPDF 最基本的使用方法如下,在终端中输入:
ocrmypdf input.pdf output.pdf -l chi_sim
其中 input.pdf 和 output.pdf 分别为初始 PDF 文档名称和要生成的 PDF 文档名称(或及其路径)。在输入初始 PDF 文档名称时,可以直接在 Finder 中复制此文件,直接在终端中粘贴。
处理完成后,就可以打开生成的 PDF 文件进行搜索或选择其中的文字了。
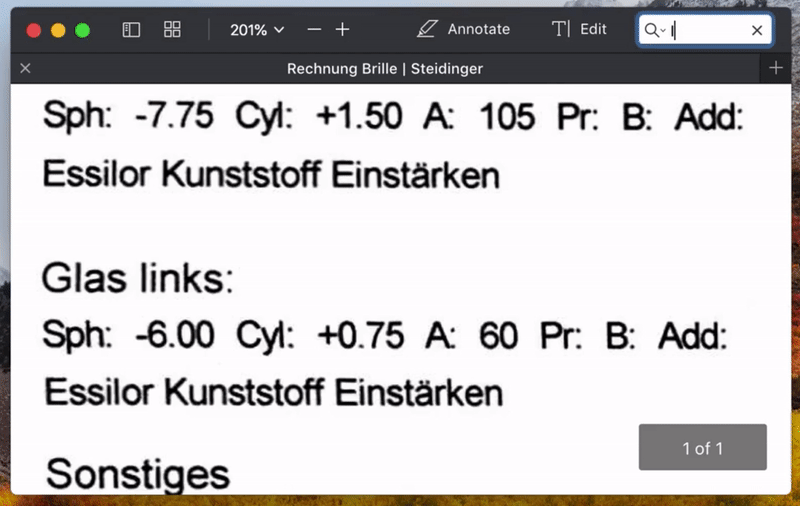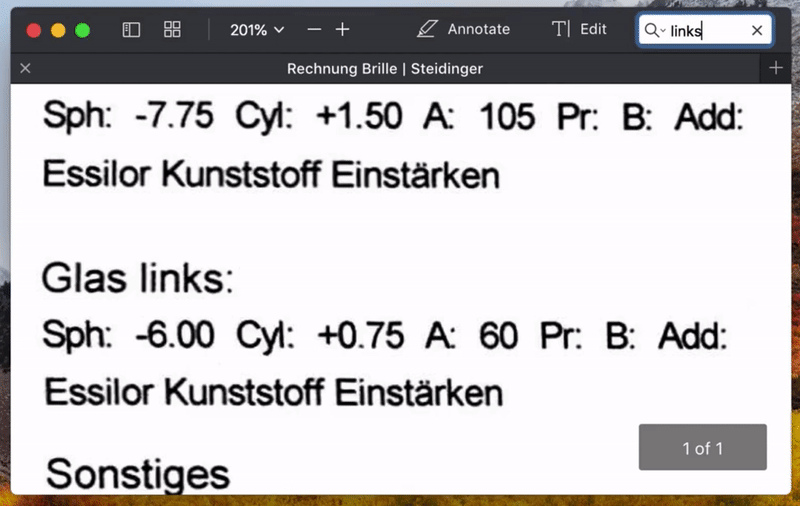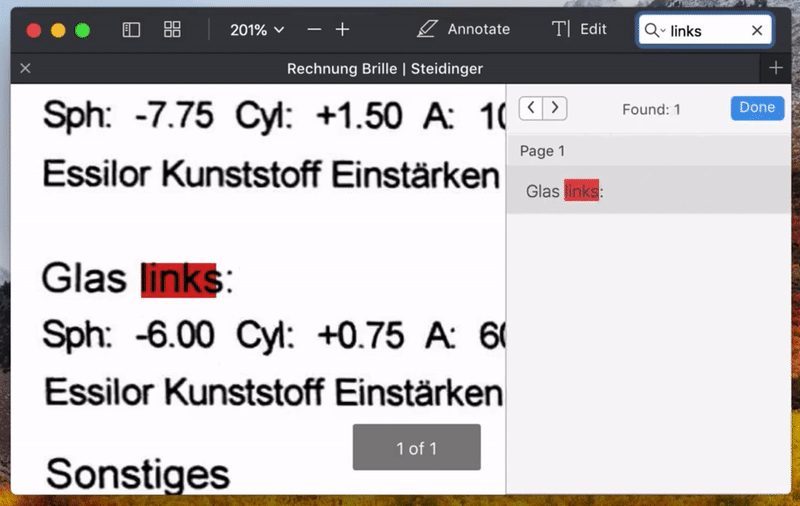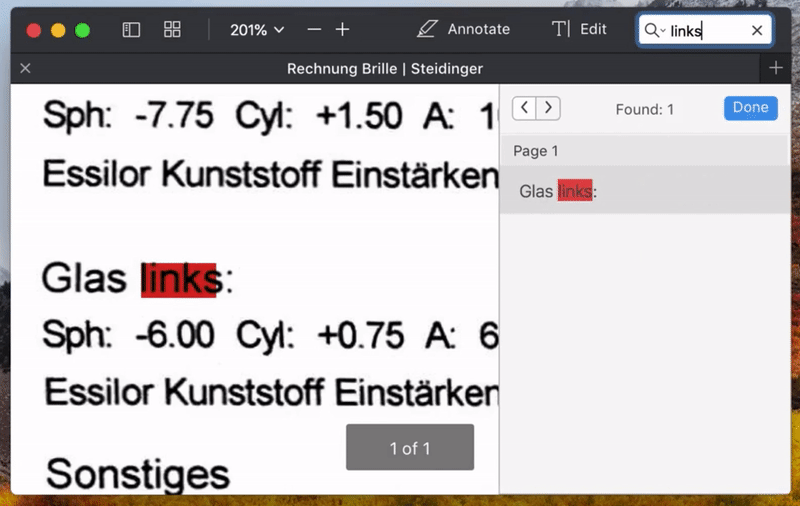
搜索 PDF
命令中 -l chi_sim 是指调用的语言包,与所下载的语言包的文件名一致。如果文档中包含多种语言,也可以通过用 + 加号连接各语言包名称来调用它们,如要识别中英双语的文档,则输入:
ocrmypdf input.pdf output.pdf -l chi_sim+eng
在处理过程中,可能会出现一些关于不确定页面朝向之类的提示,但一般不会影响最终的运行结果。
如果要直接覆盖原文件,可以直接把后者也写成前者的名称,即:
ocrmypdf input.pdf input.pdf -l chi_sim
只有在文档处理成功后,原文件才会被覆盖。
有的输入的文件中已经存在可选择的文字,则运行上述命令时会提示文档中已存在文字。当仍然有图片中的文字需要 OCR 识别的,需要再在命令中加上 --force-ocr 对文档进行强制处理:
ocrmypdf input.pdf output.pdf -l chi_sim+eng --force-ocr
作用原理
OCRmyPDF 的 OCR 功能是基于 Tesseract 引擎。Tesseract 是一套自 2006 年起由 Google 赞助的 OCR 软件,支持识别上百种语言。
OCRmyPDF 作用原理是,在识别出页面上的文字后,在文档的每一页上加一层隐形的文字图层,其中的文字位置与图片中对应文字的位置相同。这样,虽没有改变原文件的外观,但搜索关键词或选择文字时,会将隐形文字图层中对应的位置标示出来。
结合自动化工具
我们可以把上面的命令行融合入自动化工具中,以完成对 PDF 文件的自动 OCR 处理。由于 OCRmyPDF 用到了 Python,目前只有 LaunchBar 能够直接运行。
在 LaunchBar 中建立一个名为「OCR PDF File into Chinese」的动作。其运行效果如下:
将动作脚本语言选为 Python,把如下脚本写入动作脚本中:
#!/usr/bin/env python
# LaunchBar Action Script
import sys
import subprocess as sp
import os
my_env = os.environ.copy()
my_env["PATH"] = "/usr/local/bin:" + my_env["PATH"]
# Note: The first argument is the script's path
for arg in sys.argv[1:]:
# name the new file
point_postion = arg.rfind(".")
new_filename = arg[:point_postion]+"_OCR_Version.pdf"
# do OCRmyPDF
my_command = ["ocrmypdf", arg, new_filename, "-l", "chi_sim", "--force-ocr"]
sp.call(my_command, env=my_env)
# notification
my_command = ["osascript", "notification.scpt", new_filename]
sp.call(my_command, env=my_env)
其中 for 为脚本主体,用 # 注释标出了三个段落:
1. 获取目标 PDF 文件名,并在其后加上 _OCR_Verion 作为生成的新文件的文件名;
2. 执行 OCRmyPDF 命令;
3. 创建完成后弹出通知。
不足
相比目前流行的云识别,其识别质量稍显不足,但是基本满足一般的搜索需要。
我把手边很多重要的文件都用 OCRmyPDF 进行了处理,处理结果中虽然有个别错误,但整体结果仍然是另人满意的。
想要得到良好的结果,首先要确保要进行处理的文件扫描效果清晰,页面不歪斜,以便于提高识别的正确率。另外,这个工具较适合处理短小的文件(如 10 页以内),如果文件页面过多,容量过大,则需要很长时间的处理过程,出现错误的机率也会更大。另外,经过我一段时间以来的使用我感觉相比之下 Tesseract 对于英文和德文识别的正确率比中文要更高,相信有大量外文扫描文档的读者会喜欢上这个工具。
上一期
下一期
精选评论(1) 我的评论